Content Index Administration
The search index is used by search, the dashboard, some macros, and all the other places where we show information about the content in your Confluence site. The search index is made up of:
- a content index which contains content such as the text of pages, blog posts, and comments
- a change index which contains data about each change, such as when a page was last edited
These indexes are updated automatically as people get work done on your site. Changes, such as a new page, comment, or edit to an existing page, aren't updated in each index immediately. They're placed into queues and regularly processed in batches (as often as every 5 seconds) in the background as you work.
The indexing process is largely the same whether you’re running on Lucene (default), or OpenSearch. One notable difference is that with Lucene, Confluence will automatically propagate the newly-built index to other nodes.
View the index queues
It can take a while for the queues to process if there are thousands of changes to your site within a short period.
To check the contents of the queue:
- Go to Administration menu
 , then General Configuration > Content Indexing.
, then General Configuration > Content Indexing. - Select the Content queue or Change queue tab.
Here you can see the number of items in the queue, the last time the queue was processed, and how long it took to process. This information is useful for troubleshooting if your users report issues with search or dashboard activity feeds.
Rebuild the search index
There are situations where you may need to rebuild the search reindex; for example, when users report issues with search, dashboard activity feeds, or when directed to as part of an upgrade.
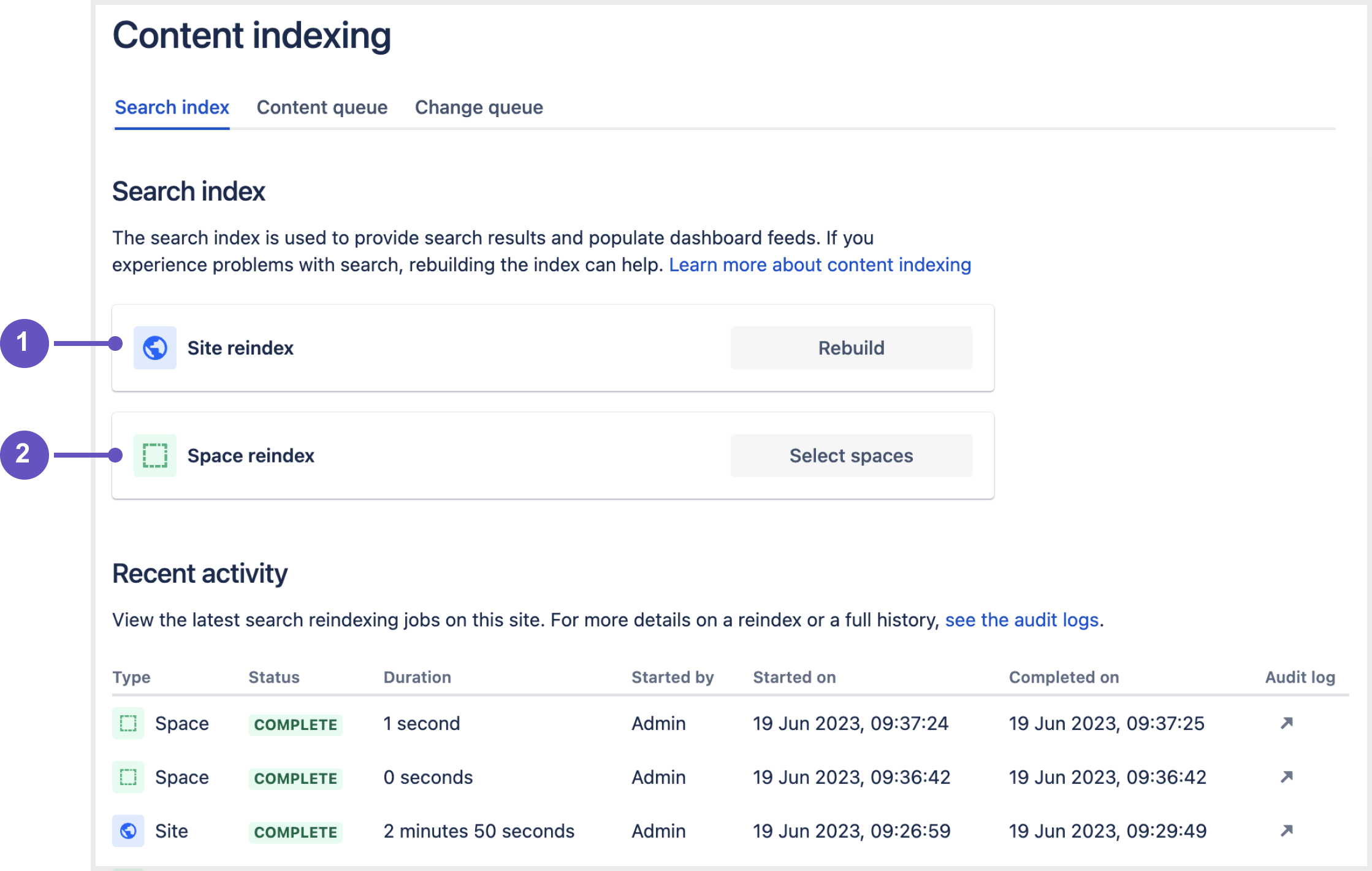
Screenshot: Search index UI screen in the admin console
You have the option to rebuild the search index for:
- an entire site
- a space or multiple spaces
You should run a space reindex when:
- you know the exact issue and the affected spaces
- you want to stagger or spread out a full site reindex
- the content index for a space is corrupted after importing it to your site
- a page is moved from one space to another, and the index for the page is corrupted in the process
You should run a site reindex when:
- a space reindex fails to resolve the issue
- a user can't be found or mentioned
- an admin can't find the target spaces when reindexing a space; this may mean the space directory index is broken
By rebuilding the search index for a site or space, you rebuild both the content index and change index. This can take some time for large sites. You should also consider this when deciding what type of reindex to run.
Reindexing a space
To reindex for one or more spaces:
- Go to Administration menu , then General Configuration > Content indexing.
- Next to Spaces reindex, select Select spaces.
- Search for the spaces by entering the space name into the field, then select those you want to reindex.
- Select Rebuild and follow the prompts to confirm you want to rebuild the index.
While reindexing spaces, search functionality becomes unavailable on all nodes for the targeted spaces. This is true for both Lucene and OpenSearch.
Reindexing a site
To reindex the entire site:
- Go to Administration menu , then General Configuration > Content indexing.
- Next to Site reindex, select Rebuild and follow the prompt to confirm you want to rebuild the index.
If you’re running Confluence with Lucene (the default search engine), the search functionality becomes unavailable on that node while performing a site reindex. Please refer to How to manually rebuild content index from scratch on Confluence Data Center without any downtime to mitigate that.
If you’re running Confluence with OpenSearch, the search functionality remains available on all nodes. This is because site reindexing is performed with the blue-green approach, where the indexing process is run on a new index while the existing index remains unaffected.
Track the progress of the reindex
You can get the status of a reindexing job in the Recent activity table. To learn more about a job (including any errors or issues that occurred), select the arrow at the end of the table row to see the a udit log for that job.
Screenshot: Search index UI screen in the admin console
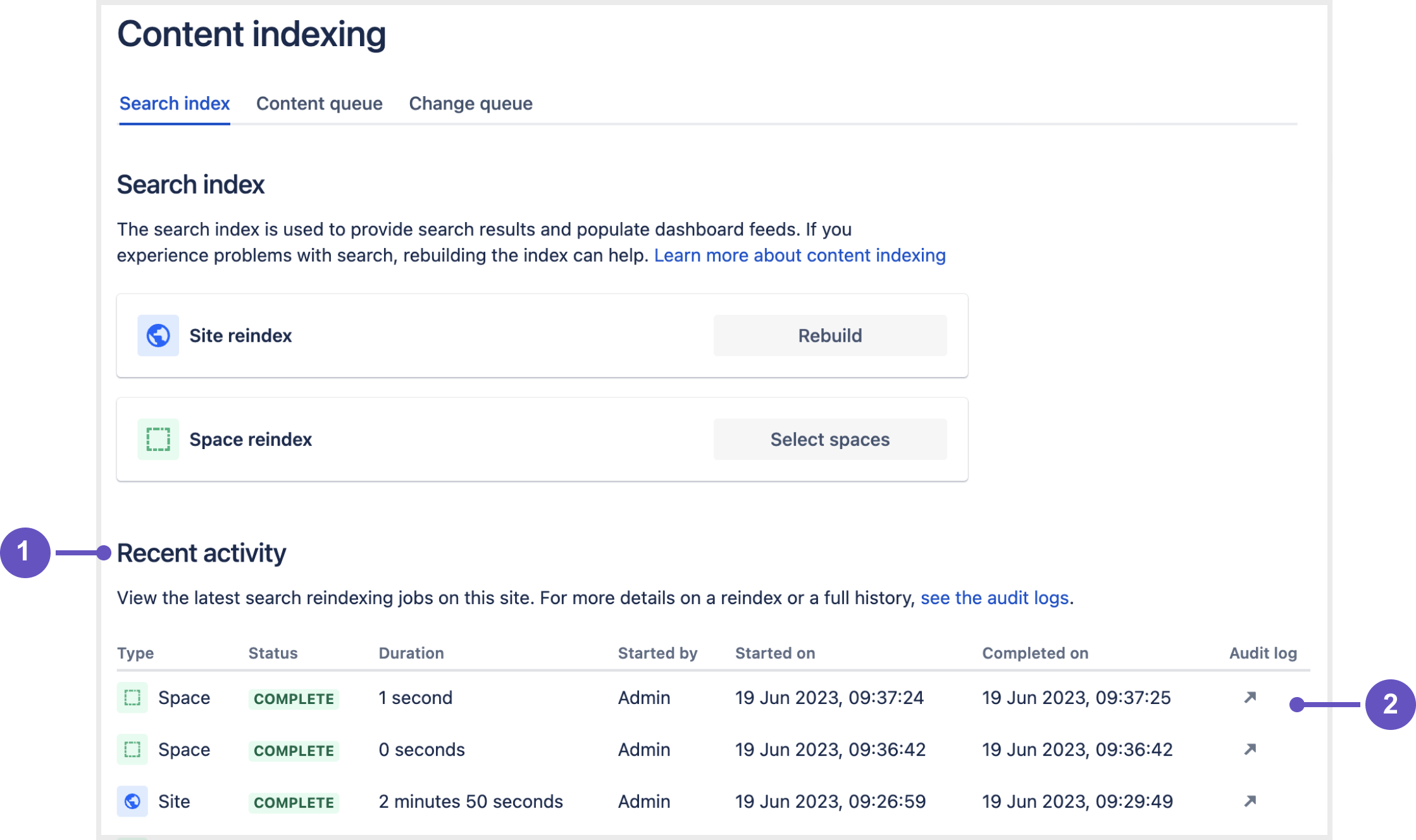
- Recent activity table
- See the audit log for a specific reindex job
For even more details, you can also check the Confluence indexing logs at atlassian-confluence-index.log (see Working with Confluence Logs for how to access these logs). Examples of the details available in the Confluence indexing logs are below:
Progress updates
Content reindexing happens concurrently in batches. The percentage of content that has been processed will be displayed regularly every time a batch of content is processed.
2023-02-02 12:16:44,342 INFO [Indexer: 1] [confluence.internal.index.ConcurrentBatchIndexer] logProgress Re-index progress: 38 of 61. 62% complete. Memory usage: 1 GB free, 2 GB totalHowever, not all content may be successfully indexed due to unhandled errors.
Unhandled errors
Unhandled errors that occur will impact content in the same batch. However, it won't impact the indexing of content in other batches. Unhandled errors will also be logged.
If you find an unhandled error, you should find out the root cause and resolve the issue before re-running the reindex.
2023-02-01 12:24:50,043 ERROR [Indexer: 1] [confluence.internal.index.ConcurrentBatchIndexer] lambda$null$2 An error occurred while re-indexing a batch. Only the particular batch which had an error occur will not be re-indexed correctly.
-- referer: http://localhost:8080/confluence/plugins/servlet/rebuildindex | url: /confluence/rest/prototype/latest/index/reindex | traceId: 0463502f0ab3faab | userName: admin
java.lang.RuntimeException: Some unhandled exception
....Reindex complete
When the progress reaches 100%, reindexing is complete.
2023-02-02 12:16:44,553 INFO [Indexer: 1] [confluence.internal.index.ConcurrentBatchIndexer] logProgress Re-index progress: 100% complete. 61 items have been reindexedKeep in mind that because of unhandled errors, it is possible that not all of your content has been successfully reindexed. The progress reflects how much content has been processed, rather than how much content has actually been successfully indexed.
Impact on end users
Users can continue to search and use Confluence but may experience some performance degradation, especially when running a site reindex. This is because rebuilding the index increases the load on your server.
Rebuilding an index can take several hours. The amount of time depends on the number, type, and size of pages and attachments on your site, the amount of memory allocated, and disk throughput.
If you have a very large site, there are some things you can do to reduce the impact on your users:
- If you're running Confluence on a single node, kick off the rebuild on a weekend, or during a scheduled maintenance window.
- If you're running Confluence in a cluster, remove the node rebuilding the index from your load balancer. Then, Confluence will then continue to use the existing index until the new index has been rebuilt successfully. Once propagation is complete, you can add the node back into the pool.
Propagate the search index to your cluster (only applicable on Lucene)
For site reindexing, once the search index is rebuilt on the current node, we automatically propagate the index files to all other nodes in the cluster.
The index files will only be propagated to nodes that have joined the cluster. If Confluence isn't running on a node, we won't be able to propagate the index to that node.
If there's a problem, for example, if a node becomes unavailable, or there's insufficient disk space to copy the index, you will see an error status like PROPAGATION FAILED. Go to the audit log for the job to find details about the error.
For space reindexing, the search index is rebuilt across all nodes concurrently so node propagation is not required.
Disk space requirements
If you run Confluence in a cluster, before you do a site reindex ensure you have enough free space in your shared home directory to accommodate an additional reindex snapshot. This snapshot is required for node propagation.
Location of search indexes
By default, Confluence uses Lucene for indexing. You can find the index in the <home-directory>/index directory.
If you're running Confluence in a cluster, a full copy of the Confluence indexes are stored in the <local-home>/index directory on each Confluence node. A journal service keeps each index in sync.
If you need to see the contents of the search index for any reason, there is a tool you can use to browse the index directly. See How to view the contents of the search index in Confluence Server and Data Center.
When using OpenSearch, the index is managed externally in your OpenSearch cluster. See Configuring OpenSearch for Confluence.
Index recovery in a cluster
If you run Confluence in a cluster, a snapshot of your site's search index is stored in the shared home directory. These snapshots are created by the Clean Journal Entries scheduled job which, by default, runs once per day.
When you start a Confluence node, it will check whether its index is current, and if not, it will request a recovery snapshot from the shared home directory. If a snapshot is not available, it will generate a snapshot from a running node (with a matching build number). Once the recovery snapshot is extracted into the index directory, Confluence will continue the startup process. The journal service will then make any further updates required to bring the index up to date.
If the snapshot can't be generated or is not received in time, existing index files will be removed and Confluence will perform a reindex on that node. If your index is very large or your file system is slow, you may need to increase the time Confluence waits for the snapshot to be generated using the confluence.cluster.index.recovery.generation.timeout system property.
Index recovery only happens on node startup, so if you suspect a problem with a particular cluster node's index, restart that node to trigger index recovery.
The index recovery snapshot isn't used when you manually rebuild your index from the UI. The rebuild process generates a brand new snapshot, before propagating it to other nodes in the cluster.
Check the size of your index
You can measure the index size in two ways, size on disk, or you can use the number of pages and blogs as a rough indication of the amount of content in the index.
To check the Lucene index size on disk:
- Go to
<local-home>/index - Check the size of that directory. The way you do this will depend on your operating system.
To check your OpenSearch index size on disk, use the cat indices REST endpoint GET _cat/indices/<index>?v. See cat indices for details.
To check the number of pages and blogs in the index:
- Go to Administration menu , then General Configuration > System information
- Scroll down to the Confluence usage section and check the Content (Current Versions) value.
Troubleshooting
If you have problems rebuilding the search index, the following may help.
Can't rebuild the index
If you're unable to rebuild the index from the Confluence UI, or if you still have problems with search after rebuilding the index, you may need to rebuild the index from scratch. The way you do this depends on whether Confluence is running in a cluster:
- How to Rebuild the Content Indexes From Scratch on Confluence Server
- How to Rebuild the Content Indexes From Scratch
Can't access content indexing page
If the content indexing page does not load properly, and you see a "We can't check the status of your index, you may have lost your connection, refresh the page to try again" error, try updating your browser to the latest version.
Poor performance while rebuilding the index
If you experience stability problems while the index is being rebuilt, you can reduce the number of threads Confluence should use to rebuild the index. Set the reindex.thread.count system property to define the maximum number of threads that can be used.
If both reindex.thread.count and index.queue.thread.count are unset, the reindex thread count defaults to the number of CPUs on that Confluence server.
Out-of-memory errors while rebuilding the index
If you experience out of memory errors while rebuilding the index, increasing the heap memory available to Confluence may help. See Fix java.lang.OutOfMemoryError in Confluence.
Rebuilt site index failed to propagate to other nodes in the cluster (only applicable on Lucene)
This generally happens when there is not enough free disk space for the local home directory on each node to accommodate two copies of the index. See Failed to propagate index in Confluence Data Center 7.7 and later to find out how to re-try the propagation.