Confluence Data Center sample deployment and monitoring strategy
At Atlassian, we use several enterprise-scale development tools. Our Confluence Data Center instance is used by about 2,400 full-time Atlassian employees, globally.
How we use Confluence
Collaboration and open communication is vital to our culture, and much of this collaboration happens in Confluence. As of April 2018, we had 14,930,000 content items across 6,500 total spaces. On a six-hour snapshot of the instance's traffic, we saw an average of 341,000 HTTP calls per hour (with one hour peaking at 456,000 HTTP calls). Based on our Confluence Data Center load profiles, we'd categorise this instance as Large for both content and traffic.
Our Confluence Data Center instance is used heavily during working hours in each of our locations, so to keep all Atlassians happy and productive, we need to make sure it performs. The instance is highly available, so an individual node failure won't be fatal to the instance. This means we can focus more on maintaining acceptable performance, and less on keeping the site running.
Infrastructure and setup
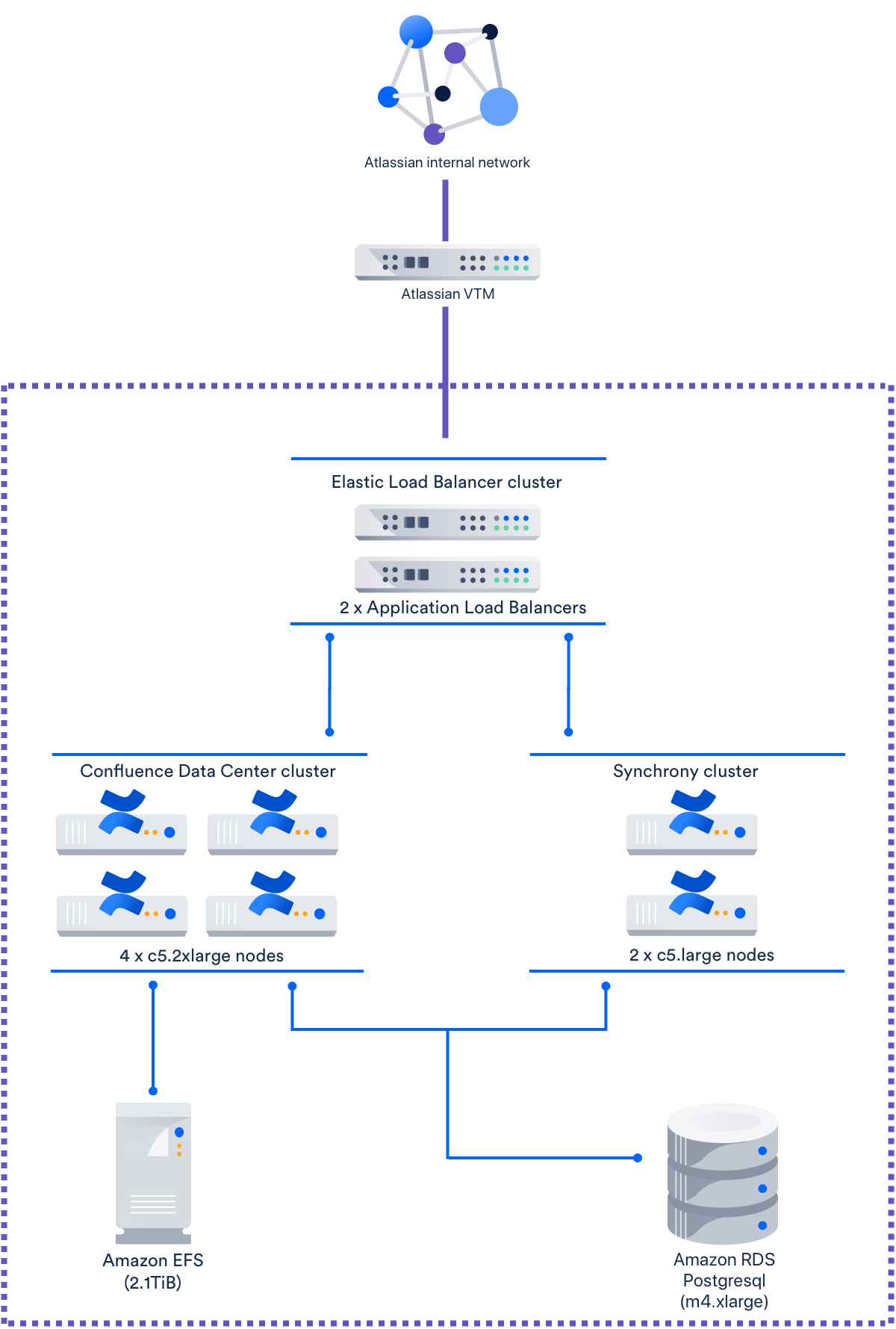
Our Confluence Data Center instance is hosted on an Amazon Web Services (AWS) Virtual Private Cloud, and is made up of the following :
Function | Instance type | Number |
|---|---|---|
| Load balancer | AWS Application Load Balancer | 2 |
| Confluence application | c5.2xlarge (running Amazon Linux) | 4 |
| Synchrony application (for collaborative editing) | c5.large (running Amazon Linux) | 2 |
| Database (Amazon RDS Postgresql) | m4.xlarge | 1 |
| Shared home directory | Elastic File System (2.1 TiB) | 1 |
Load distribution is managed by a proprietary Virtual Traffic Manager (VTM), and an application load balancer. The Atlassian VTM performs two functions:
- Routing traffic between different Atlassian instances on the same domain, and
- Terminating SSL for the Confluence Data Center instance.
The Synchrony cluster has two nodes, has XHR fallback enabled, and does not use the internal Synchrony proxy. The instance also uses 2.1 TiB of Amazon Elastic File System for storage.
Refer to the AWS documentation on Instance Types (specifically, General Purpose Instances and Compute-Optimized Instances) for details on each node type.
Integrated services
This Confluence Data Center instance has 70 user-installed apps enabled, and is linked to the following mix of Atlassian applications:
- 5 x Jira Software and Service Desk
- 7 x Confluence
- 2 x Bitbucket
- 11 x Bamboo
- 2 x Fisheye / Crucible
This instance is also connected to Crowd, for user management.
Monitoring strategy
Our performance monitoring strategy is built around targeting an Apdex of 0.7, but keeping it above 0.4. This index assumes that a 1-second response time is our Tolerating threshold, while anything beyond 4 seconds is our Frustrated threshold.
With the Apdex index, maintaining general satisfaction in the instance involves managing the ratio of "happy" and "unhappy" users. Refer to Apdex overview for more information.
Maintaining an Apdex level within Tolerating levels means actively monitoring the instance for potential problems that could cause major slowdowns. Many of these alerts, monitoring strategies, and action plans are based on previous incidents we've since learned to resolve quickly or avoid.
The following tables list our monitoring alerts, and what we do when they're triggered.
General load
| Metric we track | Alerting level | What we do when alert is triggered |
|---|---|---|
Long-running tasks | Our monitoring tools send us an alert if a user starts any of these tasks:
We also receive an alert for each hour the task continues to run. | If the task appears to be stuck and starts triggering other alerts, we'll usually restart the node and kill the task. We'll also contact the user to discuss other options. For space exports, this could mean reducing the size of the exported space, or exporting from a staging server. |
Network throughput | 20Mbps or higher (as of April 2018) | We investigate other metrics to see if anything (other than high user traffic) caused the increased throughput. Over time, we check how many times the throughput triggers the alert to see whether we need to tweak the infrastructure (and the alerting level) again. |
| Number of active database connections Having too many active database connections can slow down Confluence. | More than 1000 connections | The m4.xlarge node type supports a maximum of 1,320 connections. If a node triggers the alert and continues rising, we'll perform a rolling restart. We'll also raise a ticket against Confluence, as a bug (specifically, a database connection leak) could also trigger this alert. To date, our instance has never triggered this alert. |
Node CPU usage | We set two CPU usage alerts for application nodes:
Likewise, for the database node:
| When an application node triggers its warning alert, we perform a heap dump and thread dump and investigate further. We perform a rolling restart if we think that instance is about to crash. To date, the database node has always recovered on its own whenever it triggered its alerts. |
Garbage Collector pauses We also track this metric for development feedback. Pauses help us identify areas of Confluence that unnecessarily create a lot of objects. We analyze those areas for ways to improve Confluence. | Any Garbage Collector pause that lasts longer than 5 seconds | Usually this alert requires no action, but it can help warn us of possible outages. The data we collect here also helps us diagnose root causes of other outages. If the Garbage Collector triggers this alert frequently, we check if the instance requires heap tuning. |
Load balancer
| Metric we track | Alerting level | What we do when alert is triggered |
|---|---|---|
Number of timeouts | 300 timeouts within a 1-hour period. | This many timeouts in a short amount of time is typically followed by other alerts. We investigate any triggered alerts and other metrics to see if an outage or similar problem is imminent. |
Node health See Load balancer configuration options for related details. | Whenever the load balancer disconnects or re-connects a node. | When a node disconnects, we check its state and restart it if necessary. We also check for other triggered alerts to see what could have caused the node to disconnect. |
| Internal server errors When the load balancer returns an internal server error (error code 500), it usually indicates that there are no back end nodes to process a request. | When the load balancer encounters more than 10 internal server errors in a second. | We check for other triggered alerts to see if there's a problem in a specific subsystem (for example, database or storage). |
Storage
| Metric we track | Alerting level | What we do when alert is triggered |
|---|---|---|
| I/O on file system of shared home High I/O slows down file access, which can also lead to timeouts. | PercentIOLimit is greater than 98. This means that the shared home's file system I/O is now over 98% of its limit. See Monitoring with Amazon CloudWatch for more details. | We investigate whether we need to increase the I/O limit. |
| Disk space We need to know early if we should expand disk space to accommodate usage or check further for storage-related issues. | We set two alerts for different levels of free disk space:
| If the amount of free space is running low, but the rate of consumption remains normal, we expand the available storage. If the rate of disk consumption spikes abnormally, we check if there are misbehaving processes. This also involves checking the amount of disk space consumed within the last 24 hours. |
Stability monitoring
The following alerts relate to the instance's overall stability. They don't get triggered as often, as most of the work we do to address performance problems also prevents outages.
| Metric we track | Events we alert for | What we do when alert is triggered |
|---|---|---|
Common error conditions | Common errors we set alerts for include (but aren't limited to):
| Most of the errors we alert for are documented in the Confluence Knowledge Base, along with how to prevent them from causing an outage. |
| Hazelcast cluster membership By default, Hazelcast removes and re-adds a node if it doesn't send a heartbeat within 30 seconds. We configured ours to do this within 60 seconds instead. | When a node is removed from and re-added to the cluster. | We perform a log analysis, thread dump, and heap dump on the affected node. If any of these show a cluster panic or outage is imminent, we perform a rolling restart. |
| Cluster panics These are severe failures, and usually require a full Confluence restart. | Every time a cluster panic occurs. Our monitoring tools check the application logs for events that correlated to panics the instance experienced in the past. | We perform a full Confluence restart. This means shutting down all application nodes, and starting them up one by one. See Data Center Troubleshooting and Confluence Data Center Cluster Troubleshooting for related information. |
Non-alerted metrics
We don't set any alerts for the following metrics, but we monitor them regularly for abnormal spikes or dips. We also check them whenever other alerts get triggered, or if the Apdex starts to drop.
| Metric we track | Monitoring practice |
|---|---|
JVM memory | When JVM starts running low on memory, we perform a heap dump and thread dump. We perform a rolling restart if either dump shows that a crash is imminent. |
| Number of active HTTP threads Having too many threads in constant use can indicate an application deadlock. | If abnormal spikes in this metric coincide with deadlocks or similar problems, we restart each affected node. If they don't, we just tune thread limits or take thread dumps for further investigation. See Health Check: Thread Limit for related information. |