How to manually rebuild content index from scratch on Confluence Data Center with downtime
Platform Notice: Data Center - This article applies to Atlassian products on the Data Center platform.
Note that this knowledge base article was created for the Data Center version of the product. Data Center knowledge base articles for non-Data Center-specific features may also work for Server versions of the product, however they have not been tested. Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Summary
This KB article highlights the steps to rebuild the content index in a Confluence Data Center instance if you can afford some downtime.
If you want to check other options to rebuild the content index, go to How to Rebuild the Content Indexes From Scratch.
If you have any question about this procedure or if you encounter any problem while running the reindex, create a ticket to Atlassian Support.
Environment
This procedure is valid if you are running Confluence Data Center versions 6.x and 7.x.
Solution: Confluence 7.7 and later
From Confluence 7.7 rebuilding the index and propagating the new index to all nodes in your cluster can be done directly through the Confluence UI.
This method requires no downtime, and you can also choose to remove the node performing the reindex from your load balancer, to further minimise any performance impact on users. Confluence will continue to use the existing index until the new index has been successfully rebuilt and propagated to each node in the cluster.
See Content Index Administration for more information.
Solution: Confluence 6.0 to 7.6
The Sections below describes the procedure to rebuild the content index in Confluence Data Center.
While you run the procedure, all nodes of the Confluence cluster will be down for a period of time, meaning this requires a downtime.
While this procedure works for instances with a single or multiple nodes, in this example we will consider a Data Center deployment with 2 nodes, namely node1 and node2.
If you have a deployment with 3, 4 or more nodes run the same steps from node2 in any additional node.
If you are running in a single node, disregard the steps associated to node2.
Preparation phase
Choose the node where the reindex process will run.
There should be only one node running the reindex, while Confluence on all other nodes from the cluster will be stopped.
In this example we will choose
node1as the node to run the reindex.
On
node1configurelog4jto send indexing related log messages to a separated file.The additional messages in a separated log file is helpful to identify if the indexing process is still running or if it completed; it is also helpful in case anything goes wrong and you need to contact the support team.
Follow the instructions on Configuring log4j in Confluence to send specific entries to a different log file to send messages from target classes to
atlassian-confluence-indexing.log.The following classes should be added to INFO as part of the above procedure.
com.atlassian.confluence.search.lucene com.atlassian.confluence.internal.index com.atlassian.confluence.impl.index com.atlassian.bonnie.search.extractor
This change will only take effect when Confluence is restarted, which you don’t need to perform at this point, since it will be restarted on a following step.
Remove all nodes from the load balancer target group.
This is an optional step if you want to prevent users from accessing Confluence while the index is being rebuilt.
Confluence may be slow while reindex is running, so users might not get the best experience while accessing the application.
Cleaning the current index
- Stop Confluence on all nodes of the cluster following your standard procedure.
- If running Synchrony standalone, stop its process on all nodes.
Access the database and run the following SQL to truncate the
journalentrytable.TRUNCATE TABLE JOURNALENTRY;Take a safety backup of
index/On
node1delete the following folders.<Confluence-home>/index/ <Confluence-home>/journal/ <Confluence-shared-home>/index-snapshots/
Rebuilding the index
- Start Confluence on
node1.- This will automatically trigger the reindex on this node during the startup process.
- Track the reindex process through the
atlassian-confluence-indexing.logfile.The following entry indicates the reindex process started.
2020-06-09 17:32:05,553 WARN [Catalina-utility-1] [confluence.impl.index.DefaultIndexRecoveryService] triggerIndexRecovererModuleDescriptors Index recovery is required for main index, starting now 2020-06-09 17:32:05,557 DEBUG [Catalina-utility-1] [confluence.impl.index.DefaultIndexRecoveryService] recoverIndex Cannot recover index because this is the only node in the cluster 2020-06-09 17:32:05,558 WARN [Catalina-utility-1] [confluence.impl.index.DefaultIndexRecoveryService] triggerIndexRecovererModuleDescriptors Could not recover main index, the system will attempt to do a full re-index 2020-06-09 17:32:05,724 DEBUG [lucene-interactive-reindexing-thread] [confluence.internal.index.AbstractReIndexer] reIndex Index for ReIndexOption CONTENT_ONLYWhile reindex is running you may see entries similar to the below.
2020-06-09 17:32:14,911 DEBUG [Indexer: 4] [internal.index.lucene.LuceneContentExtractor] lambda$extract$0 Adding fields to document for Space{key='SPC550'} using BackwardsCompatibleExtractor wrapping com.atlassian.confluence.search.lucene.extractor.AttachmentOwnerContentTypeExtractor@7103c5b0 (confluence.extractors.core:attachmentOwnerContentTypeExtractor) 2020-06-09 17:32:14,911 DEBUG [Indexer: 8] [internal.index.lucene.LuceneBatchIndexer] doIndex Index Space{key='SPC632'} [com.atlassian.confluence.spaces.Space] 2020-06-09 17:32:14,910 DEBUG [Indexer: 6] [internal.index.lucene.LuceneBatchIndexer] doIndex Index Space{key='SPC530'} [com.atlassian.confluence.spaces.Space] 2020-06-09 17:32:14,909 DEBUG [Indexer: 7] [internal.index.attachment.DefaultAttachmentExtractedTextManager] isAdapted Adapt attachment content extractor com.atlassian.confluence.extra.officeconnector.index.excel.ExcelXMLTextExtractor@6aa2ced for reuse extracted textThe following entry indicates the reindex process completed successfully.
2020-06-09 17:32:31,387 DEBUG [Indexer: 1] [internal.index.lucene.LuceneContentExtractor] lambda$extract$0 Adding fields to document for userinfo: user001 v.1 (1572865) using BackwardsCompatibleExtractor wrapping com.atlassian.confluence.search.lucene.extractor.HtmlEntityFilterExtractor@4033e565 (confluence.extractors.core:htmlEntitiesFilterExtractor) 2020-06-09 17:32:31,387 DEBUG [Indexer: 1] [internal.index.lucene.LuceneContentExtractor] lambda$extract$0 Adding fields to document for userinfo: user001 v.1 (1572865) using BackwardsCompatibleExtractor wrapping com.atlassian.confluence.search.lucene.extractor.TitleExtractor@48deb96f (confluence.extractors.core:titleExtractor) 2020-06-09 17:32:31,388 DEBUG [Indexer: 1] [confluence.internal.index.AbstractBatchIndexer] lambda$accept$0 Re-index progress: 100% complete. 3276 items have been reindexed 2020-06-09 17:32:31,432 DEBUG [Indexer: 1] [confluence.internal.index.AbstractBatchIndexer] accept BatchIndexer batch complete 2020-06-09 17:32:31,491 DEBUG [lucene-interactive-reindexing-thread] [confluence.search.lucene.PluggableSearcherInitialisation] initialise Warming up searcher.. 2020-06-09 17:32:31,491 DEBUG [lucene-interactive-reindexing-thread] [confluence.search.lucene.DefaultSearcherInitialisation] initialise Warming up searcher..- Do not proceed to the next step while you don’t get a confirmation from the logs that the reindex had completed.
- Create a sample page to confirm new items are being added to the content index.
- Create a sample page with unique content and make sure it is searchable.
- You may need to wait up to 30 seconds so the new page is indexed.
- This step is important to ensure the new index is healthy and to prevent a bug reported in CONFSERVER-57681 - Site reindex should reset journal entry pointer upon successful completion to prevent the reindex run after each restart when the journal entry queue is empty.
- Access the Confluence UI and go to Cog icon > General configuration > Content Indexing > Queue Contents and confirm there’s no item to be processed.
- If there are items in the index queue, give it a couple of minutes to complete.
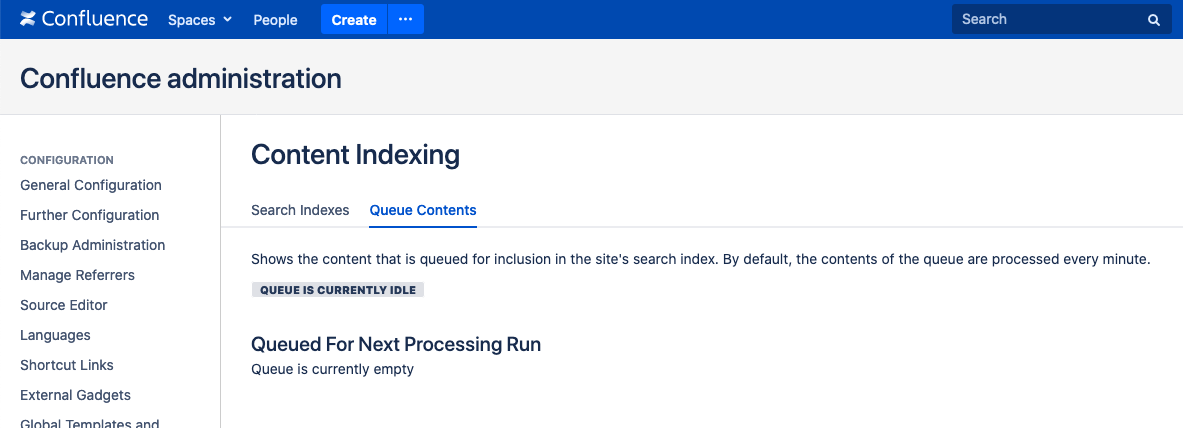
- If there are items in the index queue, give it a couple of minutes to complete.
Additional steps may be required if Questions for Confluence is installed
Follow the steps in this Section only if you have Questions for Confluence (QfC) installed and you notice that questions or topics are not searchable.
If you don't, then proceed to the next Section.
Copy the index file to a shared location
- Stop Confluence on
node1. On
node1compress theindexand thejournalfolders and save them in theshared-home.
Saving these files in the shared home make them available to the other nodes in the cluster.cd <Confluence Home Dir> tar -cvf <Confluence-shared-home>/node1-index.tar ./index tar -cvf <Confluence-shared-home>/node1-journal.tar ./journal- On
node1remove the additional logging configuration made inlog4j.properties.- These were added as part of the Preparation Phase.
- Since unnecessary debugging can negatively impact the application, it is strongly recommended you don’t keep that configuration during normal operation of Confluence.
- If running Synchrony standalone, start its process in all Synchrony nodes.
- Start Confluence on
node1and confirm it is working fine. - At this point
node1can be made available to users. Therefore, addnode1back to the load balancer target group.
Copy the index files from the shared home to the remaining nodes of the cluster
On
node2delete theindexandjournalfolders in the local home.cd <Confluence-home> rm -rf index/ rm -rf journal/On
node2uncompress theindexandjournalfolders from the shared home to the local home.cd <Confluence-home> tar -xvf <Confluence-shared-home>/node1-index.tar tar -xvf <Confluence-shared-home>/node1-journal.tarConfirm the index files were properly placed in
node2local home.
The structure should be similar to the below.$ ls -R atlassian-confluence-local-home/index atlassian-confluence-local-home/journal atlassian-confluence-local-home/index: _9.cfe _a.cfe _b.cfe _c.cfe _d.cfe _e.cfe _f.cfe _g.cfe _h.cfe _j.cfe _j_1.del segments_9 _9.cfs _a.cfs _b.cfs _c.cfs _d.cfs _e.cfs _f.cfs _g.cfs _h.cfs _j.cfs edge _9.si _a.si _b.si _c.si _d.si _e.si _f.si _g.si _h.si _j.si segments.gen atlassian-confluence-local-home/index/edge: _0.cfe _0.cfs _0.si _1.cfe _1.cfs _1.si segments.gen segments_4 atlassian-confluence-local-home/journal: edge_index main_index- Start Confluence on
node2and confirm it is working fine. - At this point,
node2can be made available to users. Therefore, addnode2back to the load balancer target group.
Cleanup tasks
Delete the compressed
indexandjournalfiles from the shared home folder.rm -f <Confluence-shared-home>/node1-index.tar rm -f <Confluence-shared-home>/node1-journal.tar
Restore Popular Content
(Optional): If desired, restore the following directories from your backup from Step 2, see Popular content missing after reindexing from scratch for instructions
Confirming content index is working on all nodes
These steps help to confirm new content is being properly indexed by all Confluence nodes.
- Access the Confluence UI on
node1and create a new sample page. - Go to Cog icon > General configuration > Content Indexing > Queue Contents and confirm all objects were processed in index queue.
- If it is still processing, wait for a minute or so for it to complete.
- Do a search on
node1for the newly created document to confirm it was indexed. - Go to
node2and access Cog icon > General configuration > Content Indexing > Queue Contents to confirm there’s no object on the indexing queue. - Do a search on
node2for the newly created document to confirm it was indexed. - Do the same validation on any remaining node of the Confluence cluster.
See also
How to Rebuild the Content Indexes From Scratch