Confluence Data Center

Confluence Data Center enables you to configure a cluster similar to the one pictured here with:
- Multiple server nodes
- A shared file system
- A database that all nodes read and write to.
- A load balancer to evenly direct requests to each node.
All nodes are active and process requests. A user will access the same node for all requests until their session times out, they log out, or a node is removed from the cluster.
Performance at scale
If your Confluence instance has a very heavy load (you have a lot of users accessing Confluence at the same time) a clustered installation will allow you to serve a greater number of concurrent requests than a single server.
Confluence Data Center spreads the load evenly between cluster nodes enabling you to serve more requests before performance degrades. It's not faster than a single node and won't improve performance in instances with a small number of users.
Instant scalability
Licensing is based on users, not the number of nodes in your cluster. This means you can join additional nodes to your cluster at any time, making it very easy to adapt as your usage grows.
Achieving high availability
High availability, or HA, means that a system is available without interruption. HA is necessary if you have SLA's or other commitments such as 99.99% up time.
If a Confluence Data Center node fails, is shut down or disconnected from the network the rest of the cluster will continue operating - as long as one node remains. When a node fails the load balancer stops sending requests to that node and redirects requests to the remaining nodes. Users will be directed to another node seamlessly.
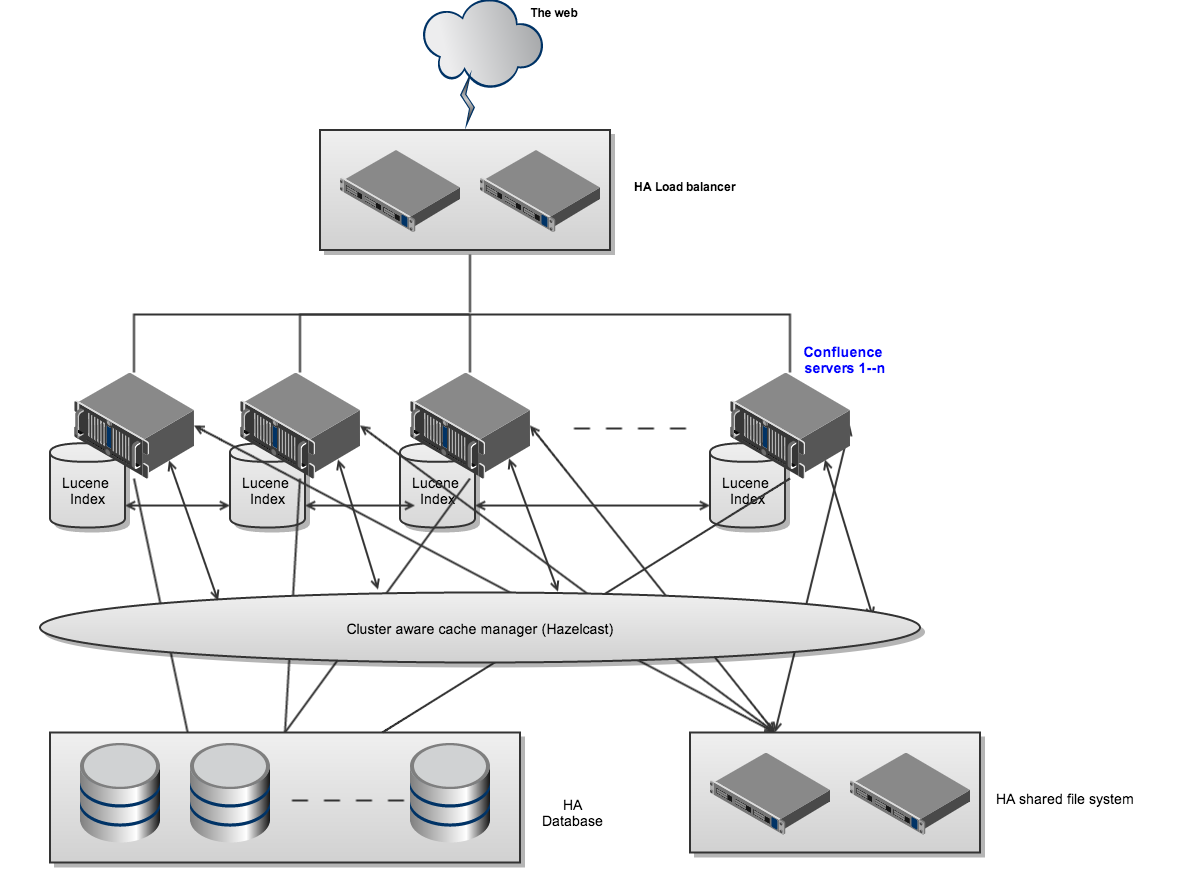
Some things you can do alongside Confluence Data Center to minimise single points of failure include ensuring that your:
- load balancer
- database
- shared file systems
- external user management
are all highly available. An example of a highly available Confluence installation is shown here.
With all of the above in place, the only time you should need to bring down your entire cluster is to upgrade Confluence itself. Confluence Data Center requires all nodes to be stopped to perform the upgrade.
Most other maintenance can be performed by bringing down individual nodes, as nodes can leave and rejoin the cluster without disruption.
Failover
It is important to note that Confluence Data Center nodes must be able to communicate between one another with minimal latency and therefore must be located in the same physical location.
Warm failover can be achieved by syncing your Confluence data to a data center in a different geographical location and switching over in the event of a failure. This solution is not automatic, and requires manual intervention, but can provide failover in the case of a major failure in your primary data center.
Ready to get started?
Contact us to speak with an Atlassian or get started with Data Center today.