Stash is reaching resource limits
Introduction
This article aims to explain the meaning of the "Stash is reaching resource limits..." banner that you might be seeing on your instance.
It is important to note that you might have two different banners displayed by Stash:
- The yellow banner indicating Stash is queuing requests or;
- The red banner that indicates that requests are actually being rejected
A yellow banner under heavy load is normal. Do not change any of your configuration parameters at this stage. Before increasing your configuration limits, you need to monitor the CPU, memory and/or I/O load on the server and verify that the box isn't thrashing, as increasing the ticket limits can worsen your instance performance. This is better explained in the following sections.
Memory budget
When deciding on how much memory to allocate for Stash, the most important factor to consider is the amount of memory required by the git operations. Stash's default JVM memory configuration (-Xms256m -Xmx768) works well for customers with large instances in our experience as Stash's heap size has zero impact on hosting operations. Most of the memory usage in a server running Stash is on the forked git processes – the git operations are very expensive in terms of memory. So allocating more memory to the Stash JVM won't help your instance scale and perform better. The effect can be exactly the opposite: if your server doesn't have enough free memory available for the forked git operations because your Stash JVM is using most of the memory, as soon as git concurrent operations start to happen, you will experience a performance loss as your server will not have enough memory to fork out more git processes.
Ok. I get that I shouldn't tweak Stash's default memory in most cases. How should I budget my server memory then?
It is a simple formula: we should focus on how many concurrent hosting tickets Stash allows as well as how much memory is used by a single clone in order to budget the memory usage.
- Memory usage by a single clone operation
As a rule of thumb, 1.5 x the repository size on disk (contents of the.git/objectsdirectory) is a rough estimate of the required memory for a single clone operation for repositories up to 400 MB. For larger repositories, memory usage flattens out at about 700 MB. For example, for a single hosting operation, as the number of memory usage for Stash remains constant at about 800MB (default) during the entire hosting operation, Git's memory usage climbs according to the rule just described.
For a detailed analysis on server's resource usage, please read through Scaling Stash - Clones examined. - Number of concurrent operations allowed by Stash
By default, Stash limits the number of Git operations that can be executed concurrently in order to prevent the performance for all clients dropping below acceptable levels. These limits can be adjusted – see Stash config properties.
The parameter used for that (throttle.resource.scm-hosting) is based on the number of CPUs that you have on your server and its formula is1.5 x cpu. - Awesome! Now I can calculate how much memory I need on my server to safely run Stash
That's all you need to know. So, for a common Stash environment the budget would be:- Stash: 768MB
- Git: 1.5 * (4 CPUs) * 700 MB = 4200 MB
- Operating System: 1024 MB
- Total: 5992 MB
- 40% safety margin: ~ 8 GB
- Please refer to Scaling Stash for more details.
Questions and answers
On the UI, the message "Stash is queuing requests" appears and it is followed later by "Stash is reaching resource limits". What does it mean?
Let's take the example described in the Memory budget section. At "Stage 1", with 4 CPUs, Stash will allow 6 SCM hosting operations to be executed concurrently, thus forking each one of them out into Git processes. If the server receives more than these 6 SCM requests, these will be queued up and won't be forked out into Git processes in order to avoid a memory exhaustion on your server. At "Stage 2", some of the Git processes initially forked out will finish processing and Stash takes requests from the SCM queue to fill in those slots. In a third stage, Stash will fork them out into new Git processes.
It is important to note that if requests are queued up for more than a minute, Stash will display the "Stash is queueing requests..." message.
If requests are queued up for more than 5 minutes (throttle.resource.scm-hosting.timeout), they are rejected and the git clone/fetch/push operation will fail. At this time, the "Stash is reaching resource limits..." message is displayed. The message will disappear when 5 minutes have passed in which no requests have been rejected (throttle.resource.busy.message.timeout or server.busy.on.ticket.rejected.within for Stash 3.0+). These parameters can be adjusted – see Stash config properties.
See an example of the data that is logged for each type of denied SCM request below:
A [scm-hosting] ticket could not be acquired (0/12)
A [scm-command] ticket could not be acquired (0/1)
To illustrate these stages, see picture below:
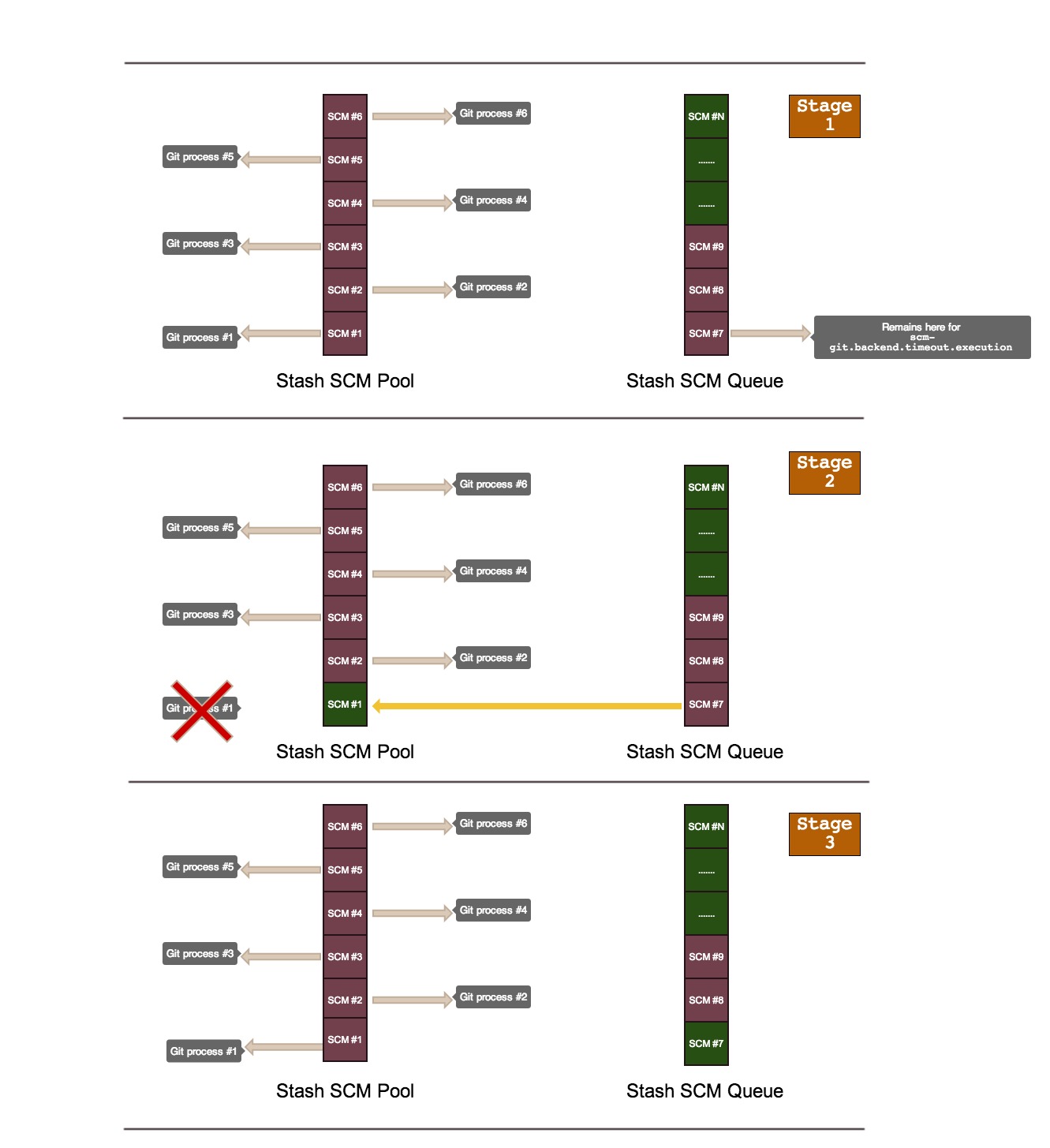
The message should be taken seriously: requests are being rejected and if this happens regularly it's an indication that your instance is not well dimensioned.
Which actions should I take to get around this issue?
As explained above, the secret is to have a queue with a number of hosting tickets that is processed quickly by your system. Even if a small queue is formed but emptied before the tickets start getting rejected you should be ok. Common mistakes that customers make and results in worse performance - don't perform those:
- Increasing the amount of memory for the Stash JVM. Don't do that! Usually, by taking this action, a lot of memory from the server is allocated to the JVM and little extra free memory is available to the Git processes being forked out by Stash. This is bad and can have side effects like the one described git push fails - Out of memory, malloc failed as the Git processes are being chocked by the lack of free memory.
- Increasing the number of hosting tickets by tweaking
throttle.resource.scm-hosting. Don't do that! The reason for not taking this action lies on what was previously explained: the system will wait up to 5 minutes (default configuration ofthrottle.resource.scm-hosting.timeout) for a ticket to free up. That said, reducing the number of hosting tickets may result in some queuing, however the individual clones tends to be processed faster due to reduced I/O contention which increases the likelihood a ticket frees up before the timeout. On the other hand, by increasing the number of hosting tickets Stash can handle, you will increase the amount of time your CPUs are processing the forked out Git processes as there will be more which in turn decreases the likelihood of a ticket to be freed up before the timeout.
Below are a few actions that should help you get your Stash processing hosting tickets faster. Please consider these:
Continuous Integration polling
Reduce the frequency your CI servers are checking out repositories from Stash. This is a common point reported by customers hitting this issue. If you have a large number of Git operations happening on Stash, you're likely to have the "Stash is reaching resources limits..." message. Make sure your CI servers are reasonably keeping Stash busy and reduce polling when possible. Make sure you have the SCM caching plugin turned on and up-to-date as described in Scaling Stash for Continuous Integration performance.
SSL processing
Running SSL all the way through to Stash is another common issue we see in customers hitting this issue. For a better performance, you really need to setup a proxy in front of Stash. The Java SSL stack is nowhere near as efficient as any of those and removing this will result in much more efficient processing from Stash. Please see Proxying and securing Stash on how to perform this change.
Ref advertisement caching
The ref advertisement feature is disabled by default as explained in Scaling Stash for Continuous Integration performance under the Caching section. However, it can produce a noticeable reduction in load when enabled. You shouldn't need to restart Stash to accomplish that; you can change it at any time using the REST API calls detailed in Enabling and disabling caching.
Server resources
It is important to ask yourself the questions below:
- How much memory?
- How many CPUs?
Budget your server accordingly. Refer to the Memory budget section as well as Scaling Stash for more details on how to do this.
- Plugins: As explained, this issue has a lot to do with processing. Make sure you don't have any plugins affecting your performance. We've had experience with Awesome Graphs: it is a nice plugin but the indexing it does is CPU and IO intensive and can dramatically affect the performance of a Stash instance. If your system is already under heavy load, we advise you to disable all user installed plugins for a period of observation. Follow the instruction in Set UPM to safe mode.
- Processing: A strategy here could be adding more CPUs to the machine while keeping the concurrency max at your current system's default. So let's say you have 4 CPUs reported by your system. Your current SCM hosting ticket number is 6. Adding more CPUs and keeping the concurrency queue on its previous state, will help you process those 6 hosting tickets quicker, leaving the extra requests queued up for a shorter period, thus, yielding a better flow of tickets. Hence, this will give you more capacity to handle the same load and improve the overall performance while the server is busy performing hosting operations.
You can keep the current concurrency limit by adding the following configuration to your stash-config.properties (create one if it doesn't exist and restart Stash so it will load the new file):
# Limits the number of SCM hosting operations, meaning pushes and pulls over HTTP or SSH, which may be running concurrently.
# This is intended primarily to prevent pulls, which can be very memory-intensive, from pinning a server's resources.
# There is limited support for mathematical expressions; +,-,*,\ and () are supported. You can also use the 'cpu'
# variable which is resolved to the number of cpus that are available.
throttle.resource.scm-hosting=6
How can I monitor the SCM hosting tickets usage without resorting to a thread dump analysis?
There are two ways to monitor Stash's ticket counts, depending on what exactly you want from your monitoring.
The first approach is to write a plugin. Stash raises TicketAcquiredEvent, TicketReleasedEvent and TicketRejectedEvent at all the times you'd expect events with those names to be raised. Each event includes the bucket the ticket came from. You'd want to monitor the "scm-hosting" ones; "scm-command" ones are used for trivial operations like git diff and git rev-list and are never held for more than a couple of seconds at a time.
If you choose to go down this route, please take care to do as little processing as possible in your @EventListener method. If you need to do a lot of processing, please create an ExecutorService of your own to do it on. Tying up Stash's event threads can result in strange behavior.
The second approach is to add the following line to stash-config.properties and restart Stash:
logging.logger.com.atlassian.stash.internal.throttle.SemaphoreThrottleService=TRACE
This will enable trace logging specifically for the ticketing system. With that in place you'll start seeing messages like these:
2014-04-07 22:48:32,492 TRACE [http-bio-7990-exec-3] bturner 1368x89x0 qt8gqa 192.168.30.1 "POST /scm/AT/stash.git/git-receive-pack HTTP/1.1" c.a.s.i.t.SemaphoreThrottleService Acquired [scm-hosting] ticket (5/6)
2014-04-07 22:48:46,266 TRACE [http-bio-7990-exec-3] bturner 1368x89x0 qt8gqa 192.168.30.1 "POST /scm/AT/stash.git/git-receive-pack HTTP/1.1" c.a.s.i.t.SemaphoreThrottleService Released [scm-hosting] ticket (6/6)
The count is shown at the end, showing (available/total). In other words, on the first line it's showing one ticket is in use (not five) out of 6, and on the second it's showing that all 6 tickets are available again. You'll also see lines for "scm-command" tickets, but it's unlikely those counts will ever matter much; we've never yet had a customer have issues with "scm-command" tickets because their lifecycle is so brief.
I can't identify my performance culprit. What's the next step?
Please open an issue with Atlassian Support. Make sure of the following:
- You downloaded the logparser tool and ran the
generate-access-logs-graph.shon your Stashatlassian-stash-access*.logsas per instructions on its page. Attach the graphs to the issue. If you can't run the tool, that's ok. We will run it for you based on your Support Zip. - You have your instance debug logging on
- You have your instance profile logging on: this item is very important as it is through it we can see which process is taking a long time to be finished
- You generated the Support Zip (Administration -> Atlassian Support Tools -> Support Zip -> Create) after the problem happened. Pleased attach to the support issue and make sure Limit File Sizes? is unchecked.