Jira Data Center sample deployment and monitoring strategy
At Atlassian, we use several enterprise-scale development tools, especially when it comes to our customer-facing services. The following two services are good examples:
- getsupport.atlassian.com (uses Jira Service Management to manage support requests)
- jira.atlassian.com (uses Jira Software to track feature development and bug fixes for each product)
Both services are backed by separate Jira Data Center instances. To date, both instances track a total of 1.9 million tickets, with a combined user base of around 4.8 million users.
Jira Data Center 8.4 monitoring features
We've introduced several monitoring features in Jira Data Center 8.4, which was released months after the publication of this article. If you're looking for updated information on how to monitor the performance of your Jira Data Center deployment, see Jira Data Center monitoring.
How our Jira Data Center instances are used
Both getsupport.atlassian.com and jira.atlassian.com are used by customers and Atlassian employees across all time zones. This translates to a much larger user base than other instances we've covered before. Since they're public-facing services, we need to maintain high availability and good response times. This allows us to demonstrate that Jira Software Data Center and Jira Service Management Data Center can perform well under heavy, enterprise-grade load.
Atlassian support and development teams also use these services to track tickets collaboratively with customers and partners. This makes both services crucial to how we collaborate with people outside the company.
Both instances get heavy traffic throughout the day, with some (mostly predictable) major spikes. As Data Center instances, they're both highly available, so an individual node failure won't be fatal. We can then focus less on maintaining uptime, and more on managing performance.
Infrastructure and setup
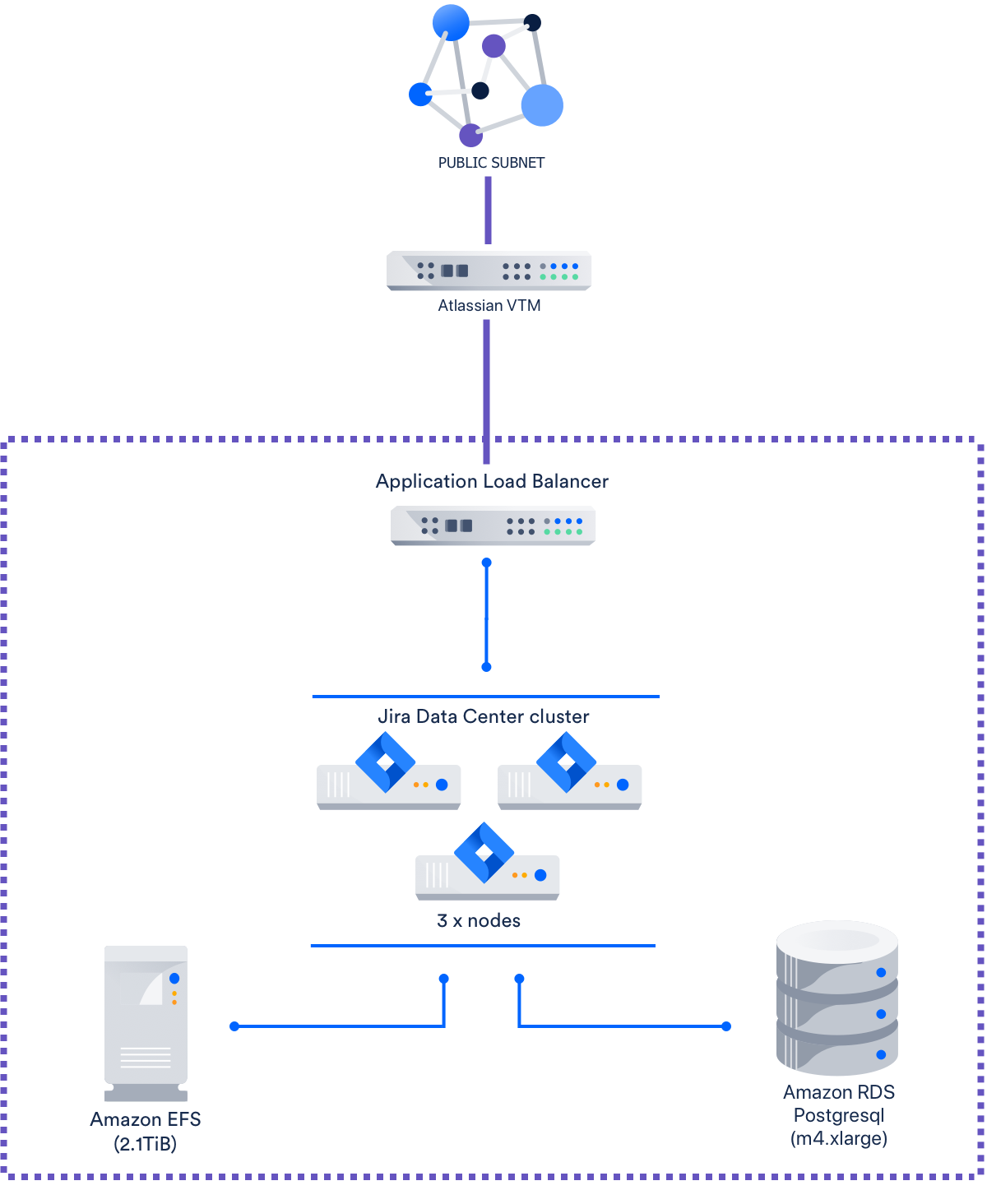
Both Jira Data Center instances are hosted on separate Amazon Web Services (AWS) Virtual Private Clouds. Their topologies and configuration are identical except for the nodes used for the database and application cluster:
| Function | Instance type | Number | |
|---|---|---|---|
| getsupport.atlassian.com | jira.atlassian.com | ||
| Jira application | m4.4xlarge | 3 | |
| Database (Amazon RDS Postgresql) | db.m4.2xlarge | 1 | |
| Load balancer | AWS Application Load Balancer | 1 | |
| Storage and file system | Elastic File System | 3 | |
Each node in getsupport.atlassian.com's Jira application cluster uses one local 240GB disk, storing both /root and Jira index cache. In jira.atlassian.com, the application cluster nodes use a separate 40GB disk for /root and 30GB disk for the Jira index cache. The getsupport.atlassian.com instance has almost double the number of issues compared to jira.atlassian.com, which accounts for the large difference in disk size. In addition, both instances' application clusters do not auto-scale (as we don't support this).
Other than the node types and the size of each application node's disk, getsupport.atlassian.com and jira.atlassian.com are configured identically:
Component | Configuration |
|---|---|
| Database (Amazon RDS Postgresql) | The database node uses General Purpose SSD storage, with single-instance High-Availability enabled. |
| Load balancer | The load balancer has only one target group. |
| Storage and file system | Each instance uses 3 Elastic File System shared volumes, one for each of the following:
|
| JVM | 24GB maximum heap size, using the G1 Garbage Collector |
Application nodes | Each node also has swapping disabled. We did this because swapping can slow down Jira’s performance. Instead, we set a maximum heap size of 24GB, using the G1 Garbage Collector. This helps ensure the node always has enough memory (which means it’ll never need to swap anyway). |
Integrated services
The getsupport.atlassian.com instance has 43 user-installed apps enabled, while jira.atlassian.com has 40. Both instances use OpenID to authenticate users directly against an Active Directory store.
The following table shows each instance's mix of linked Atlassian applications:
| Atlassian application | getsupport.atlassian.com | jira.atlassian.com |
|---|---|---|
| Jira | 11 | 13 |
| Confluence | 5 | 8 |
| Bitbucket | 0 | 2 |
| Bamboo | 0 | 17 |
| Fisheye/Crucible | 0 | 2 |
| Others | 1 | 1 |
Monitoring strategy
We keep a different update cadence for both instances; getsupport.atlassian.com gets updated every Long Term Support release, and jira.atlassian.com with each feature release. We quickly apply the latest bug fix release for each as well.
Most updates apply fixes and optimizations that help prevent outages or serious problems we've had in the past. Given our update cadence, this makes it tricky to set alerts, since thresholds that we set for one release might quickly become irrelevant in the next. In our experience, problems rarely persist across releases.
Instead, our alerts focus on a broader range of potential problems – as in, they also have to alert us of problems we've never had before. We use alerts that have consistently warned us of upcoming problems, even new ones, through multiple releases. The following sections explain the alerts and practices we use.
Focusing on sustained spikes
Both getsupport.atlassian.com and jira.atlassian.com get regular traffic spikes that can drive up resource usage. These spikes can sometimes hit critical levels (for example, 90% of CPU usage), but Jira can recover gracefully from most of them. Because of this, setting an alert for when metrics hit certain thresholds can set off many false positives.
What we do monitor, however, are sustained spikes. We want to know when a node's resource has been overworked for too long – that is, when a metric stays too long within a certain threshold. To do this, we set three dimensions for each node alert:
- Time period
- Warning level
- Critical level
We use third-party monitoring tools to take samples of certain metrics and calculate whether the metric stays within certain thresholds for the set time period. This allows us to ignore, for example, when a node has less than 10% of free disk space. Rather, we get alerted when it's had less than 10% of free disk space for 10 minutes.
Node
| Metric we track | Time period (minutes) | Warning level | Critical level |
|---|---|---|---|
IOWait | 10 | > 15% | > 30% |
System CPU time | 5 | > 80% | > 90% |
Remaining disk space | 10 | < 10% | None |
Usable memory | 5 | < 5% | < 3% |
JVM
We use third-party tools to regularly check whether Jira's processes are still up. We also use the following alerts to monitor the health of the JVM on all application cluster nodes. These alerts help warn us that the instance might slow down, or a node is about to go offline.
| Metric we track | Time period (minutes) | Warning level | Critical level |
|---|---|---|---|
Garbage Collection time | 5 | > 10% | > 20% |
Java Heap memory consumed | 5 | > 90% | > 95% |
Monitoring HTTP response
We measure the HTTP response time of getsupport.atlassian.com and jira.atlassian.com to get a quick overview of their performance. To do this, we periodically ping both instances from three US regions. Our on-duty admins are automatically notified whenever:
- HTTP response time is 7-10 seconds (warning)
- HTTP response time is 10 seconds or more (critical)
- A ping returns any HTTP return code that is not 200 (OK) or 302 (Redirect)
Load balancer health checks
Every 30 seconds, we run an automated health check request on the load balancer. The request times out after 29 seconds, at which point we’ll run another one.
If the load balancer times out two consecutive times, it is labeled unhealthy. The health check requests will continue anyway. The load balancer will be labeled healthy again once it responds successfully to two consecutive health checks.
Our on-duty admins get notified once the load balancer is labeled unhealthy. If it’s healthy by the time the admin starts investigating, they check how long the load balancer took to recover.
Log rotation
We stream our logs in real-time to a separate server. This allows us to combine logs from all nodes, and analyze the clusters as a whole. We include the node ID in each streamed log statement in case we need to trace isolated problems to specific nodes.
Streaming and storing logs on a separate server also means we can delete old logs from each node every hour. Each node will automatically delete logs that are more than five hours old. We automated this to prevent logs from consuming too much disk space. This is critical for the database, which becomes unresponsive if its node runs out of disk space (when this occurs, the entire instance goes offline).
We're here to help
We also introduced a number of monitors you can use to analyze bottlenecks and get alerts for notable events. For more information, see Jira Data Center monitoring.