Interpreting cross-product metrics for in-product diagnostics
Platform Notice: Cloud and Data Center - This article applies equally to both cloud and data center platforms.
Support for Server* products ended on February 15th 2024. If you are running a Server product, you can visit the Atlassian Server end of support announcement to review your migration options.
*Except Fisheye and Crucible
Cross-product metrics for JMX monitoring and in-product diagnostic are used across Data Center products: Jira, Jira Service Management, and Confluence. Learn more about how cross-product metrics are used and how to interpret them:
If you're searching for definitions of Jira-specific metrics for in-product diagnostics, check the article Interpreting Jira-specific metrics for in-product diagnostics.
db.connection.latency
db.connection.latency is measured by running a simple, consistent SQL query on a regular schedule.
Consistently high latency can significantly impact the performance of Jira and Confluence.
The pre-calculated aggregations are available via JMX as db.connection.latency.statistics:
_meanand_50thPercentile(median) provide a measure of the most common value of latency.A system without database latency issues should show common latency of <0.5 ms.
_maxand_meanmeasure the statistical spread of data.A large spread indicates high variability in latency, with some latency measurements significantly longer than others.
The aggregations in db.connection.latency.statistics will be reset after you restart the system or disable JMX monitoring or in-product diagnostics.
The raw measurements are available via JMX as db.connection.latency.value. This metric identifies any patterns to high latency measurements that may justify further investigation.
Here’s a sample plot showing a time series of database latency measurements in milliseconds (ms), overlaid with Mean, Max, and 99th Percentile for the time period. The values are generally below 5 ms with occasional, irregular spikes of between 10-60 ms.

Learn more about database latency:
db.connection.state and db.connection.failures
db.connection.state and db.connection.failures record when the connection to the database is lost. They are measured by monitoring database queries for connection failures.
The raw measurements are available via JMX as _value. Frequent, long-lived, or persistent failures indicated with the value -1 are likely to have an impact on the performance.
A cumulative count of failures is available via JMX db.connection.failures.counter. If _value is increasing, you should investigate the reason for the increase.
db.connection.failures.counter will be reset after you restart the system or disable JMX monitoring or in-product diagnostics.
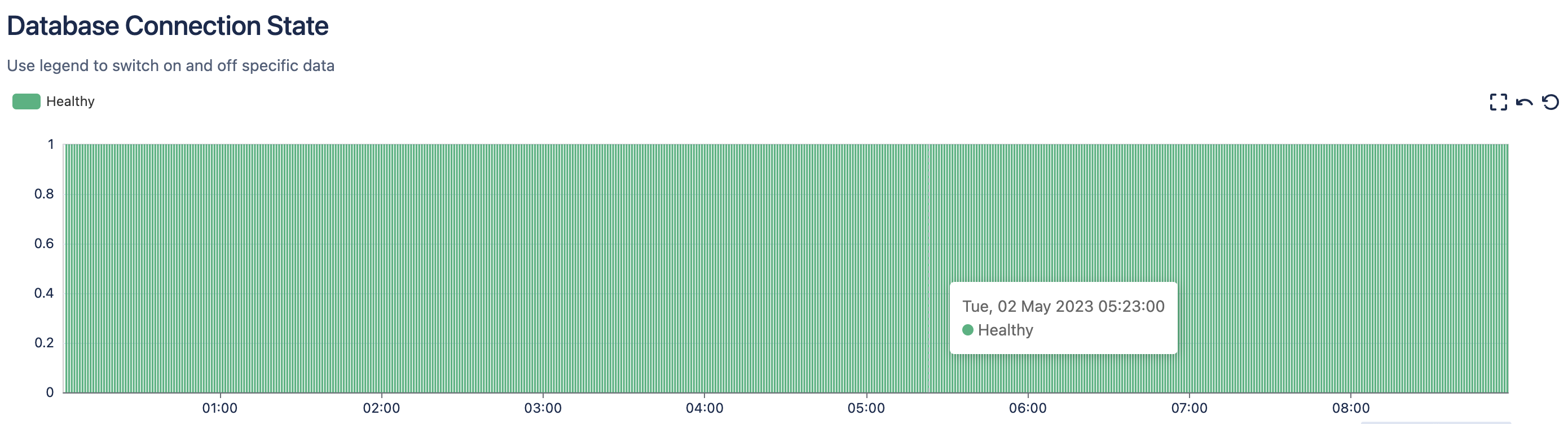
Here’s a sample plot showing a time series of database connection state measurements: 1 for connected ones and 0 for disconnected ones. The values remain 1 for the entire time period.
The following sample plot shows a time series of counts of database connection failures: 1 for each connection failure. The count is 0 for the entire time period.

db.connection.pool
db.connection.pool.numIdle and db.connection.pool.numActive measure the health of the connection pool.
The following conditions indicate that the system is starved of database connections:
numActivespikes to consume a full connection pool:_valuefromdb.connection.pool.numActive.valueis equal to_valuefromdb.connection.pool.numIdle.value.
numActiveis consistently high:_meanor_50thPercentilefromdb.connection.pool.numActive.statisticsis within 10% of_meanor_50thPercentilefromdb.connection.pool.numIdle.statistics.
This situation might lead to slow or failed responses to users. You should check http.connection.pool for any consumption of HTTP connections.
The aggregations in db.connection.pool.numActive.statistics and db.connection.pool.numIdle.statistics will be reset after you restart the system or disable JMX monitoring or in-product diagnostics.
Here’s a sample plot showing a time series of concurrent measurements of active and idle connections in a database connection pool. The active count is below 5 with occasional, irregular spikes to below 10 for the entire time period. The idle count is almost constantly at 20, with very occasional drops to between 18-20. The active count is always lower than the idle count.

Learn more about database connection pools:
http.connection.pool
http.connection.pool.numIdle and http.connection.pool.numActive measure the health of the connection pool.
The following conditions can cause outages for users as the system is unable to serve their requests:
numActivespikes to consume a full connection pool:_valuefromhttp.connection.pool.numActive.valueis equal to_valuefromhttp.connection.pool.numIdle.value.
numActiveis consistently high:_meanor_50thPercentilefromhttp.connection.pool.numActive.statisticsis within 10% of_meanor_50thPercentilefromhttp.connection.pool.numIdle.statistics.
In these cases, you should check db.connection.pool for any consumption of database connections.
The aggregations in db.connection.pool.numActive.statistics and db.connection.pool.numIdle.statistics will be reset after you restart the system or disable JMX monitoring or in-product diagnostics.
Here’s a sample plot showing a time series of concurrent measurements of active and idle connections in an HTTP connection pool, overlaid with a Max Threads count. The active count is approximately 0 with occasional, irregular spikes of up to 150 for the entire time period. The idle count varies in blocks approximately between 100 and 200. The active count is always lower than the idle count.

Learn more about HTTP connection pools: