How indexing works in Jira
Theoretical introduction
What and why use Lucene indexes
Apache Lucene is a full-text search engine library designed for fast searching across a large amount of data. Lucene search indexes are made from the text data, not directly, which is the key to achieving fast search response times. The basic unit of index and search in Lucene is the document which is built from fields . Each field is a simple tuple with a name and value . Lucene index is built from multiple documents.

Where indexes are stored
Jira stores Lucene indexes in the Jira home directory. Indexes are also stored in form of snapshots, which are just Lucene indexes packed into an archive (zip, tar or tar.sz). Such snapshots are stored in the Jira home directory and, if Jira is running in the cluster, in a shared directory.
What we are indexing
We are indexing the following entities:
issues
comments
worklogs
changes in issues (change history)
Issue and change history are indexed always when reindexing issues, but comments and worklogs are only in some specific cases. Also, issue fields in which changes are indexed may differ between Jira versions and even instances, as with Safeguards in the index project we stop indexing changes of all fields and limit it to only 6 basic fields:
Assignee
Fix Version
Priority
Reporter
Resolution
Status
Change history group VS change history item
Change history item represent change made on some field, like priority or assignee. Change history group is group of change history items, which were created within one edit operation. For example, when user edit issue in Edit issue view , multiple fields can be modified, as assignee, priority and so on. When user accept those changes by pressing update , change history items will be created for each changed field and grouped in one change history group. Even one change made on some filed will be packed into change history group.
Change history group with multiple change history items | Change history group with single change history item |
|---|---|
|
|


Indexers locally
Index flow diagram
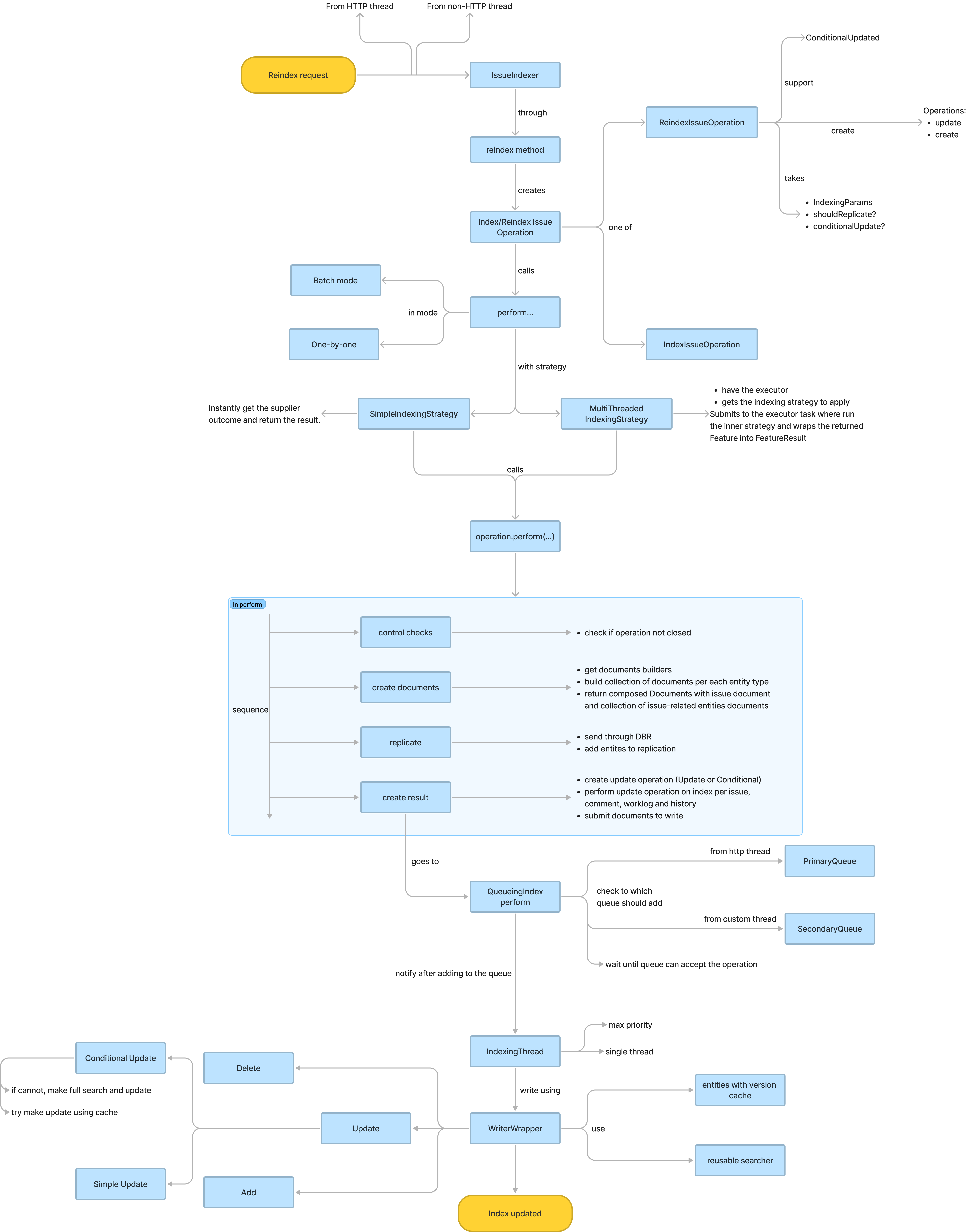
Types of requesters
Locally, ie. in given node, index request can come from two sources:
users
plugins, scripts or automations
Main difference between those two sources is the thread which is performing indexing action. HTTP threads are considered as “users” and non-HTTP threads are typically created by some plugins.
This difference has a major impact for how the index request is handled on writer level.
In the thread that call reindex , both all issues as well as single issue, we are going to perform three key actions included in the indexing operation:
creating Lucene documents
sending those documents to the other nodes
writing created documents to the local Lucene index
Create Lucene documents
As in Jira we are indexing issues, change history, worklogs and comments, each of the entity has separate Lucene document.
Each Lucene document has fields expressing data and metadata about the represented entity, as creator of the entity, date of creation, project id to which this entity belongs etc.
Indexing strategies
Documents may be created, replicated and added to write into index in parallel, depending on which indexing strategy is used. In Jira there are two indexing strategies:
simple strategy
multithreaded strategy
When using simple strategy, each main operation is performed one by one by caller thread. Multithreaded strategy takes the operations and run them in separate threads.
Writing documents to local index
Writing documents to local index is the last major action in indexing flow. It happens after the documents replication. Even though operations may be performed in parallel by multiple threads, writing to the local Lucene index is single threaded. Depending if the reindex operation is called from the HTTP thread or from the custom thread, write operation will be added to one of the following queues:
primary queue
secondary queue
Role of primary and secondary queue
Primary queue is used to handle index operation coming from HTTP thread and secondary queue is used to index operation from custom threads.
Primary queue has higher priority when it comes to actual writes into local index.
Why HTTP threads have higher priority
Two queues have been introduced to unblock user actions. Multiple reindex operation triggered by custom threads can overload the queue. Because we divide it into two queues and primary queue has higher priority, plugins or incoming replication operations will not cause slow down of user actions (which may lead to even timeouts).
Index writer with conditional update cache
To perform conditional update on index, Jira needs to open index searcher, which is expensive operation, and search for given entity for, in the next step, compare the version of founded entity with the version to which will be updated.
To avoid opening searcher for each entity separately and searching for this entity, Jira has conditional update caches. Jira caches opened searcher and, in separate cache, entities ids with current version of those entities. When the conditional update operation comes to IndexWriter , Jira check if the searcher and entity to be updated are present in cache. In case when writer found those object in the cache, Jira will not load data from local index, just write to the index if needed.
Important aspect of those caches is they are not preloaded with data. They will be filled with data when the update comes to the writer.
Whole cache is cleared always when delete operation is performed on the local index.
Stats
https://confluence.atlassian.com/jirakb/troubleshooting-performance-with-jira-stats-1041829254.html
https://confluence.atlassian.com/jirakb/jira-stats-logs-1041078856.html
Safeguard in index
Safeguard in index project was about limiting the number of issue-related entities which are indexed: worklogs, comments and change history items.
Why
Customers may have issues with a large number of comments, worklogs or change history items.
When indexing an issue with 1 hundred thousand comments, we are going to update the version table 1 hundred thousand times then make another 1 hundred thousand conditional searches and potentially update the index, make updates for the replication table with 1 hundred thousand pairs, and in the same time, we are going to serialize the index document to send through DBR. The most expensive part of this index flow is the conditional updates because this is the part where 1 hundred thousand operations are processed by 1 thread through one queue (the secondary one).
After this, the remaining nodes need to update their indexes as well, based on the DBR message and replication table, where potentially again we have hundreds of thousands of conditional updates. Also, some plugins or automations may trigger reindex operations very often.
It is enough to have one heavy issue to slow down the whole cluster by making him focus on indexing, even if the primary queue is empty or almost empty and user actions are not blocked by processing the index operations.
What we are limiting and how
This project changes what is included in issue-related entity indexes. Jira is no longer indexing all of them, instead, get the N latest and index only those. Worklogs and comments are simple, because we just get all of them, sort them by updateTime and got N’s latest entities. The situation with change history is a little bit more complicated.
As we are not indexing each change history item, but joining them in groups, those groups are indexed. Also, limits are applied to groups, not to each item. The process of indexing change history is as follows:
get all change history items
create groups from the history items
check which fields should be included (basic six or all)
got items for selected fields
join them in the group by
changeGroupId
sort the groups by
createTimeget N latest entities
Properties
We provide a set of system properties to control the safeguards in index behaviour.
Property name | Default value | Description |
|---|---|---|
| 500 | A maximum number of comments that will be indexed. |
| 100 | A maximum number of change history groups that will be indexed. |
| 100 | A maximum number of worklogs that will be indexed. |
| false | If only changes of 6 basic fields should be included in the indexed change history. |
Stats
https://confluence.atlassian.com/jirakb/jira-indexing-limits-stats-1125876330.html
Reference
https://confluence.atlassian.com/jirakb/introducing-safeguards-to-jira-index-1131089657.html
Entity versioning
Every time an entity gets indexed we increment its version stored in helper table and the index document.
Why?
Jira does not support 2 phase commits between DB and index. Because of that it was prone to race conditions when entity was updated in multiple requests.
Thread 1: saves the issue to DB with status DONE
Thread 1: triggers reindex
Thread 1: reads the issue from DB to create lucene document.
Thread 2: saves the issue to DB with status In Progrss
Thread 2: triggers reindex
Thread 2: reads the issue from DB to create lucene document.
Thread 2: updates the index with IN progress
Thread 1: updates the index with DONEAs a result the status of the issue is not consistent against DB. Additionally other nodes in the cluster will reflect the state of the DB by replaying RIO table in correct order. We created inconsistency across the nodes.
Entity versions eliminate that problem by giving a means to resolve conflicts between concurrent updates.
Implementation
Versioning tables:
issue_version
comment_version
worklog_version
SELECT * FROM issue_version
issue_id parent_issue_id update_time index_version deleted
10100 null 2020-04-30 16:30:41.985660 4 N
24727 null 2020-05-12 20:15:52.297080 3 NIn version 9.0 we've added an upgrade task that sets the version of all entities to at least 1. In Jira < 9.0.x any version is considered newer than no version.
Version fields:
issues:
_issue_versioncomments:
_comment_versionworklogs:
_worklog_versionchange history:
_issue_version
The reason that and additional table is needed and we can’t rely i.e on updated document field is that it comes from a node and there is no guarantee this time is consistent across the nodes. The versioning tables serve as a single source of truth.
Versioned issue re-index lifecycle:
bumping the version for the entity (or entities) involved
loading the version
loading the entity: we need to build the document with the version loaded before the entity so that: a document in version X contains always data from “at least” version X
building the document with the version to index and adding it to local index
Conditional update
Say we have an entity document that’s ready to be inserted into the local index. Before we do this insertion, we first search the index to check if this entity already exists there with a newer version. If this is the case, we skip putting the document in the index.
Thread 1: saves the issue to DB with status DONE
Thread 1: triggers reindex and starts with bumping the version of issue to 2
Thread 1: reads the version and then the issue from DB to create lucene document with version 2
Thread 2: saves the issue to DB with status IN PROGRESS
Thread 2: triggers reindex and starts with bumping the version of issue to 3
Thread 2: reads the version and then the issue from DB to create lucene document with version 3
Thread 2: performs conditional update. Because the current version is 1 the version it’s trying to insert (3) “wins”. We update the index with IN progress
Thread 1: performs conditional update. Because the current version is 3 the version it’s trying to insert (2) “losses”. It aborts the update.As a result the index is left in a state consistent with a DB.
We replace document if the version is the same because it is possible to trigger re-index in Jira core without version bump but changed data. i.e background re-index.
The edge case
The one corner case that needs to be handled is update vs delete.
Thread 1: saves the issue to DB with status DONE
Thread 1: triggers reindex and starts with bumping the version of issue to 2
Thread 1: reads the version and then the issue from DB to create lucene document with version 2
Thread 2: deletes the issue from DB
Thread 2: triggers reindex and starts with bumping the version of issue to 3
Thread 2: performs conditional update. Because the current version is 1 the version it’s trying to insert (3) “wins”. We delete the document from index.
Thread 1: perform conditional update. Because the document doesn’t exist we insert it with version 2.Solutions
DC:
Creating an replicated index operation with the version and consuming it by doing a conditional update of operations in version ordering.
This way even if initial course of action is performed in wrong order it’s fixed later.
The wrong order in RIO table can’t happen because bumping a deleted version is blocked.
In server mode DC (one node DC without cluster.properties file)
A delayed replay of DELETE operations to guarantee index consistency; this is not based on the index operation replication table but on the versioning entity table
Versioning logs and stats
Logs
Versioning logs are prefixed with “VERSIONING” tag.
$ cat ./log/atlassian-jira.log | grep "VERSIONING"`
Stats
Most interesting bits
requestMillis- how much time in millis all aspects of versioning took per request:"avg":28- 28 millis on average;"max":16236- looks scary, let’s look at the distribution:"distributionCounter":{"1":4,"5":257,"10":430,"50":306,"100":11,"200":1,"9223372036854775807":3}This reads as follows. From
1012create issue requests, we had the following distribution:under 1 millis: 4 requests
1 - 5 millis: 257 requests
5-10 millis: 430 requests
10-50 millis: 306 requests
50-100 millis: 11 requests
100-200 millis: 1 request
> 200 millis: 3 requests - this is an unacceptable amount of time, but it only happens for 3 create issue requests out of 1012 (< 0.3%)

requestCount- count of calls to the versioning manager during a request, here:"avg":9requestPercent- how much of the create issue request time was consumed by versioning:"avg":1(0-100)
Replication
NodeReindexService
Every Jira node runs an indexing service called NodeReindexService . Its job is to periodically (every 5 seconds) replay operations from ReplicatedIndexOperation table. The NodeReindexService is only re-indexing operations older than 15 seconds.
To distribute index change from one node to another we would create a record in the table that would be picked up by NodeReindexService of another node. The other node would then reindex entities indicated by the record.
This was the primary mechanism of index distribution before DBR was introduced.
replicatedindexoperation table
create table replicatedindexoperation
(
id numeric(18) not null
constraint pk_replicatedindexoperation
primary key,
index_time timestamp with time zone,
node_id varchar(60),
affected_index varchar(60),
entity_type varchar(60),
affected_ids text,
operation varchar(60),
filename varchar(255),
versions text
);
create index node_operation_idx
on replicatedindexoperation (node_id, affected_index, operation, index_time);
This table stores operations that are picked up and processed by NodeReindexService.
nodeindexcounter table
create table nodeindexcounter
(
id numeric(18) not null
constraint pk_nodeindexcounter
primary key,
node_id varchar(60),
sending_node_id varchar(60),
index_operation_id numeric(18)
);This table tracks the progress of replaying index operations on every node. The progress is tracked between every pair of nodes. For every node we keep track of what was the last successful operation replayed produced on every other node. Nodes also run the counter for themselves to keep track of local operations.
Special case index distribution: full foreground and background reindexes.
These are special because they do not bump versions when re-indexing and as a result they don’t replicate changes to other nodes.
Instead after completion they create index snapshot at shared home and add a special entry to RIO table
+-----+--------------------------+-------+--------------+-----------+------------+----------------------+----------------------------------------+--------+
|id |index_time |node_id|affected_index|entity_type|affected_ids|operation |filename |versions|
+-----+--------------------------+-------+--------------+-----------+------------+----------------------+----------------------------------------+--------+
|11658|2022-09-08 07:09:12.449366|383cad |ALL |NONE | |FULL_REINDEX_END |IndexSnapshot_10100_220908-170912.tar.sz| |
|11660|2022-09-08 07:11:12.137896|383cad |ALL |NONE | |BACKGROUND_REINDEX_END|IndexSnapshot_10101_220908-171112.tar.sz| |
+-----+--------------------------+-------+--------------+-----------+------------+----------------------+----------------------------------------+--------+
When NodeReindexService detects such operations it recovers the index from the snapshot indicated by the entry.
DBR
While ensuring index consistency is important the other aspect we care about deeply is performance.
When we look closely it turns out that creating documents is the most expensive step of re-indexing. It’s heavily impacted by any custom field (or rather dozens of custom fields our customers tend to have). The idea behind the DBR is to create documents once on origin nodes, serialize them and distribute over the network.
Learn more about DBR on a dedicated page.
Index startup flow
Before Jira 9.1 the default behavior of Jira was to request index in form of a snapshot from any other node if it was missing more than 10% of issues and there was no fresh snapshot in shared home.
Since 9.1 the flow changed. The requesting was turned off. To startup fast Jira is required to have a fresh index snapshot in shared home.
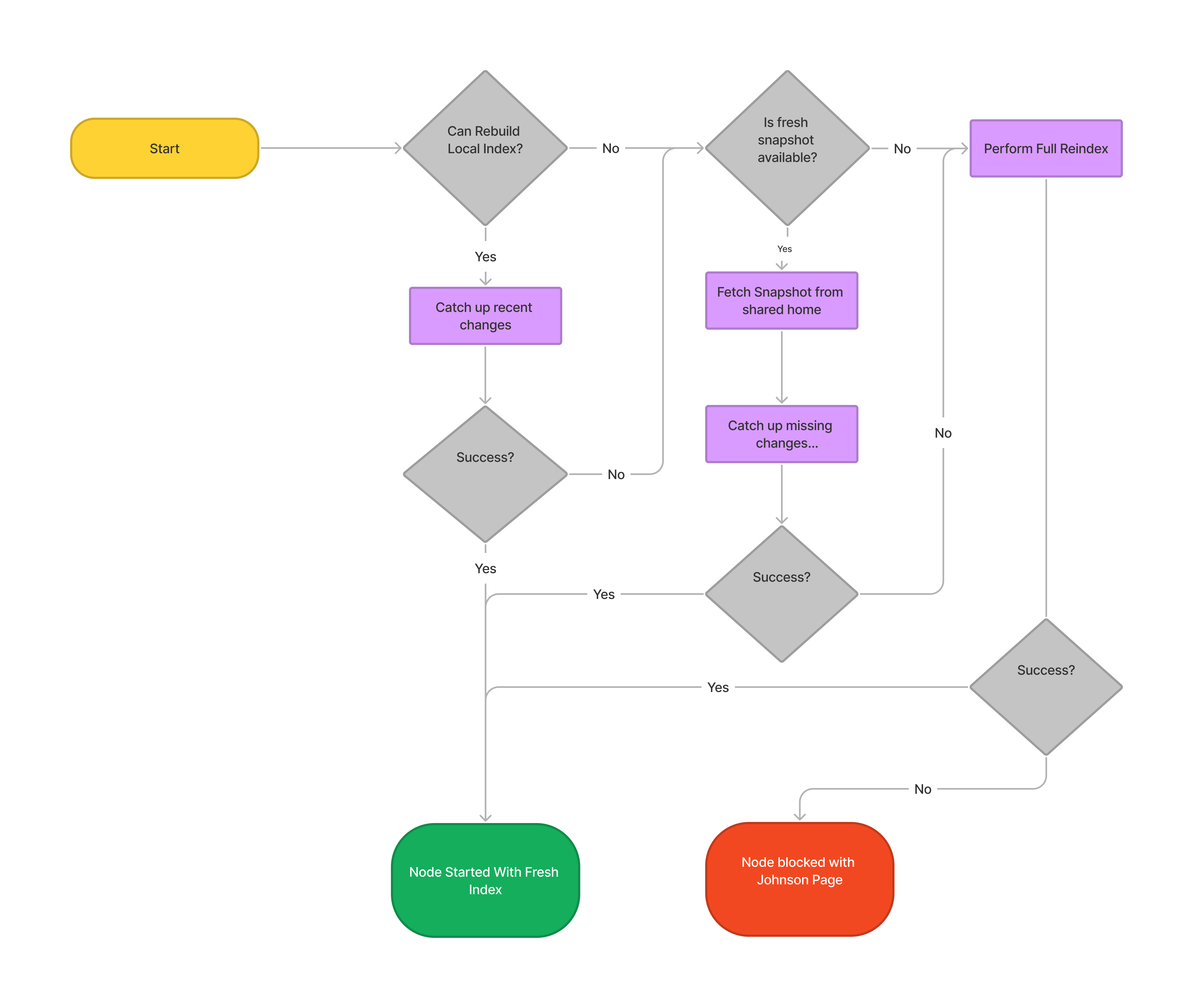
More on index management during node startup: https://confluence.atlassian.com/jirakb/index-management-on-jira-start-up-1141500654.html